
🍪#2 How To Sanitize A Filename
A developer's guide to practical defenses against unsafe file names in file upload features.

File name sanitization is a crucial process in applications handling file uploads to ensure user-provided names are both safe and compatible with the systems where they will be stored or processed. It involves validating and modifying the original names of uploaded files to prevent security threats or operational failures that could compromise system integrity.
How Attackers Exploit File Names
At first glance, a file name looks harmless. But to an attacker, it’s an opportunity. Because many applications don’t treat them as untrusted input, they can be abused in clever and dangerous ways.
Injection payloads
The risk can come not from the file itself but the way the name is processed. If an application fails to sanitize properly, malicious strings in file names can trigger existing vulnerabilities:
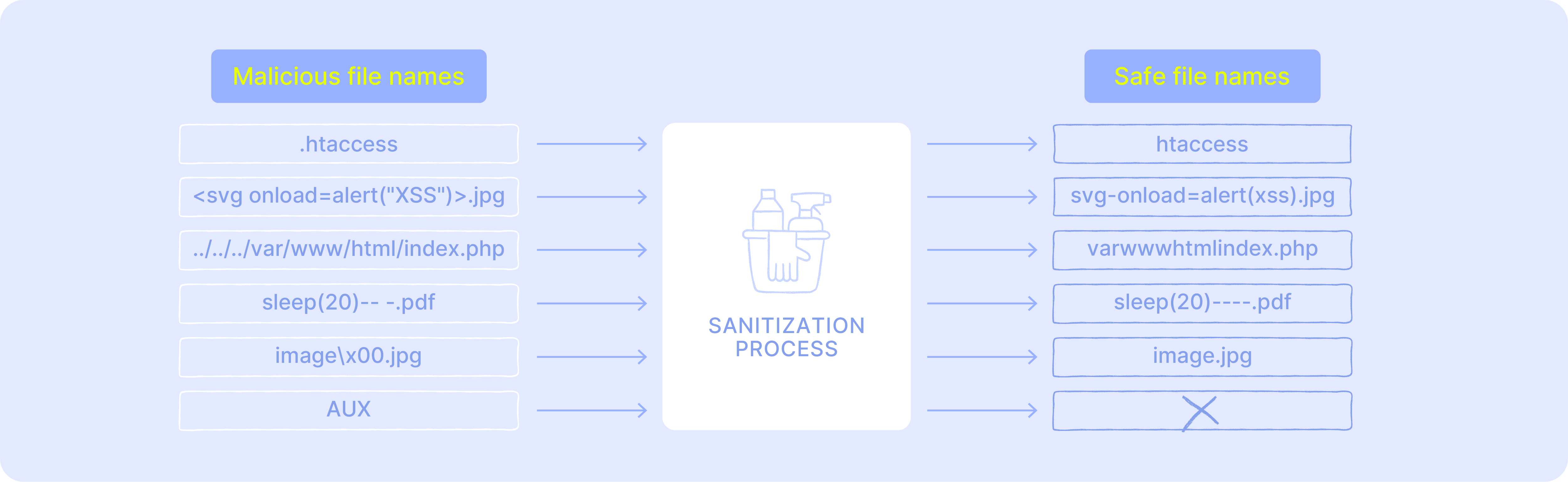
sleep(20)-- -.jpg→ can lead to SQL injection if the file name is concatenated unsafely into a SQL query without proper escaping or parameterization.<svg onload=alert("XSS")>.jpg→ can lead to Cross-Site Scripting (XSS) when the file name is reflected into a web page (HTML, attribute, or JS context) without proper encoding, or when user-supplied SVG content is served/executed in the browser.; sleep 20;.jpg→ can lead to OS Command injection if the file name is passed by concatenation into a shell or system API.
Enumeration leaks
When uploaded files are renamed poorly, attackers can predict or brute-force file names and access other users’ content. For instance, if an application simply appends a counter to duplicates:
First upload:
profile.jpg→ stored asprofile.jpg.Second upload:
profile.jpg→ stored asprofile_2.jpg.Third upload:
profile.jpg→ stored asprofile_3.jpg.
An attacker could guess profile_2.jpg, profile_3.jpg, etc., and retrieve private files from other users.
Extension tricks and truncation
Some systems enforce file name length limits, and mishandling them can introduce vulnerabilities. On Linux, where file names are limited to 255 bytes, a crafted example could be:
aaaa...[very long string]...php.pngThis may bypass a code-based filter yet still be interpreted as PHP if application logic trims or slices names improperly, for example, by truncating the trailing .png to prevent exceeding the length limit.
Path traversal
By sneaking in ../ sequences, attackers can climb outside the intended upload directory and place files where they don’t belong:
../../../../var/www/html/index.phpThis could overwrite the main application file with malicious content.
As seen, file names may appear harmless, but neglecting to verify them becomes a security risk.
The code snippet below shows an insecure file upload using multer in an Express app where the user’s original file name is used without validation:
const multer = require("multer");
const storage = multer.diskStorage({
filename: (req, file, cb) => {
cb(null, file.originalname); // Using file name provided by the user
}
});This pattern exposes the application to path traversal, injection attacks, hidden or double-extension files, accidental overwrites and cross-platform naming collisions.
Best Secure File Name Practices
As a developer, whenever possible, you need to generate unique and random file names (e.g., UUIDs or GUIDs) instead of relying on user-provided names. This solves both operational errors caused by duplicate names and security vulnerabilities tied to user-controlled file names.

If business requirements make this approach unfeasible, then apply these safeguards:
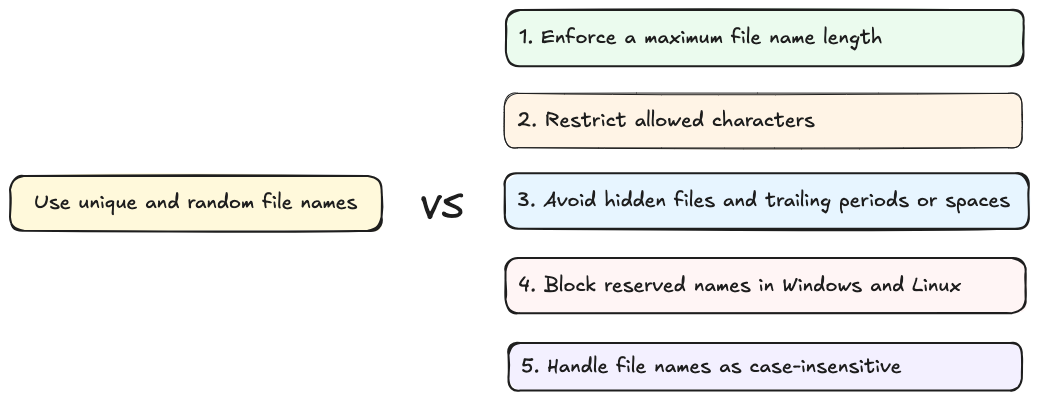
Enforce a maximum file name length.
Restrict allowed characters (e.g., A-Z, a-z, 0-9, -, _, and .).
Avoid hidden files and trailing periods or spaces (e.g., .htaccess).
Block reserved names in Windows and Linux.
Handle file names as case-insensitive.
Use Unique and Random File Names
Assigning random and unique names to uploaded files prevents file name collisions, mitigates path traversal attacks, hides original names that could reveal sensitive data, blocks injection attempts, and protects against file enumeration.
This approach is particularly useful in scenarios where the original file names provided by users do not need to be retained:
const uuid = require("uuid");
const storage = multer.diskStorage({
filename: (req, file, cb) => {
cb(null, `${uuid.v4()}.pdf`);
}
});In this illustrative case, the code uses a UUID to generate unique names and enforces the .pdf extension assuming the application is restricted to PDF uploads.
When Business Needs Prevent Random Naming
Sometimes applications need to preserve user-provided names for usability, compliance, or business logic. In those cases, security should not be sacrificed—you still can apply strict safeguards to keep file handling safe.
Enforce a maximum file name length
Different operating systems impose different limits on file name length. Legacy systems like FAT only support the old 8.3 format, while file systems like NTFS allow up to ~255 characters per filename, and ext4 allows up to 255 bytes. Excessive filename length can result in truncation, storage errors, or extension loss that lets files be misread or executed differently. Defining a safe maximum length (for example, 100 characters) prevents both technical complications and potential abuse:
const MAX_FILENAME_LENGTH = 100;
const decodedFilename = decodeURIComponent(file.originalname);
if (decodedFilename.length > MAX_FILENAME_LENGTH) {
throw new Error("File name too long");
}Restrict allowed characters
Not every character is safe in a file name. Allowing symbols, control characters, or special operators can backfire—creating risks such as path traversal or injection attacks. A safer approach is to limit file names to a small set of characters, for example: letters (A–Z, a–z), numbers (0–9), dots (.), underscores (_), and hyphens (-). Keeping names simple and predictable helps avoid cross-platform issues and reduces the attack surface significantly:
// Keep only alphanumerics, dots, underscores, and hyphens
const restrictedFilename = decodedFilename.replace(/[^A-Za-z0-9._-]/g, "");Avoid hidden files and trailing dots or spaces
File names that begin with a dot are hidden on UNIX-like systems (for example, .htaccess used by Apache). Attackers can exploit this to disguise malicious uploads or override server configuration. Similarly, names ending with spaces or periods are handled inconsistently across operating systems, sometimes causing access errors or unexpected behavior. Stripping leading dots (unless explicitly allowed) and removing trailing spaces or periods closes this gap and keeps uploaded files predictable and safe:
// Strip leading dots and trailing dots/spaces
const trimmedFilename = restrictedFilename.replace(/^[.]+|[.\s]+$/g, "");Block reserved names
File systems enforce restrictions on certain names that cannot be used for files. In Windows, names such as CON, AUX, PRN, NUL, and COM1–COM9 are reserved, and characters like <, >, :, ", /, \, |, ?, and * are not allowed. In Linux and other UNIX-like systems, the null character (\x00) and the forward slash (/) are forbidden in names, while . and .. are reserved as directory references. Filtering these values during validation prevents uploaded files from conflicting with the operating system or breaking file system logic:
const sanitizeFilename = require("sanitize-filename");
// Remove system-reserved filenames
const sanitizedFilename = sanitizeFilename(trimmedFilename);This example uses the npm package sanitize-filename, which automatically strips unsafe characters and reserved names, simplifying validation.
Treat file names as case-insensitive
On Linux, Report.pdf and report.pdf are two different files. However, on Windows and MacOS, they’re treated by default as the same file. This mismatch can cause confusion, accidental overwrites, or even unauthorized access. A reliable way to prevent this is to normalize every file name to lowercase (or uppercase) and treat them as case-insensitive. This ensures consistent behavior regardless of where your application runs:
// Normalize casing for consistency across platforms
const normalizedFilename = sanitizedFilename.toLowerCase();It’s important to keep the order of the operations, otherwise a later step can undo the protections of an earlier one—for example, restricting characters after stripping leading dots could still leave an unsafe name. By applying checks in the right sequence—decode, check length, restrict characters, strip dots and spaces, block reserved names, normalize case—you ensure every safeguard actually holds.
Interesting Reads
Some interesting articles I read in the past days: